VideoDoodles: Hand-Drawn Animations on Videos with Scene-Aware Canvases

Abstract
We present an interactive system to ease the creation of so-called video doodles – videos on which artists insert hand-drawn animations for entertainment or educational purposes. Video doodles are challenging to create because to be convincing, the inserted drawings must appear as if they were part of the captured scene. In particular, the drawings should undergo tracking, perspective deformations and occlusions as they move with respect to the camera and to other objects in the scene – visual effects that are difficult to reproduce with existing 2D video editing software. Our system supports these effects by relying on planar canvases that users position in a 3D scene reconstructed from the video. Furthermore, we present a custom tracking algorithm that allows users to anchor canvases to static or dynamic objects in the scene, such that the canvases move and rotate to follow the position and direction of these objects. When testing our system, novices could create a variety of short animated clips in a dozen of minutes, while professionals praised its speed and ease of use compared to existing tools.
Results
Short summary
Video doodles are an emerging mixed media art that combines video content with hand-drawn animations to produce unique and memorable video clips. Here is an example by LeopARTnik:
Artists typically create video doodles by drawing 2D animations frame-by-frame, using the video as an underlay. The main difficulty faced by artists following this manual workflow is to make the drawn content interact convincingly with the video content.
We propose to assist the creation of video doodles with a user interface that leverages depth and motion priors to anchor scene-aware canvases in the captured video, onto which users can add hand-drawn frame-by-frame animations.
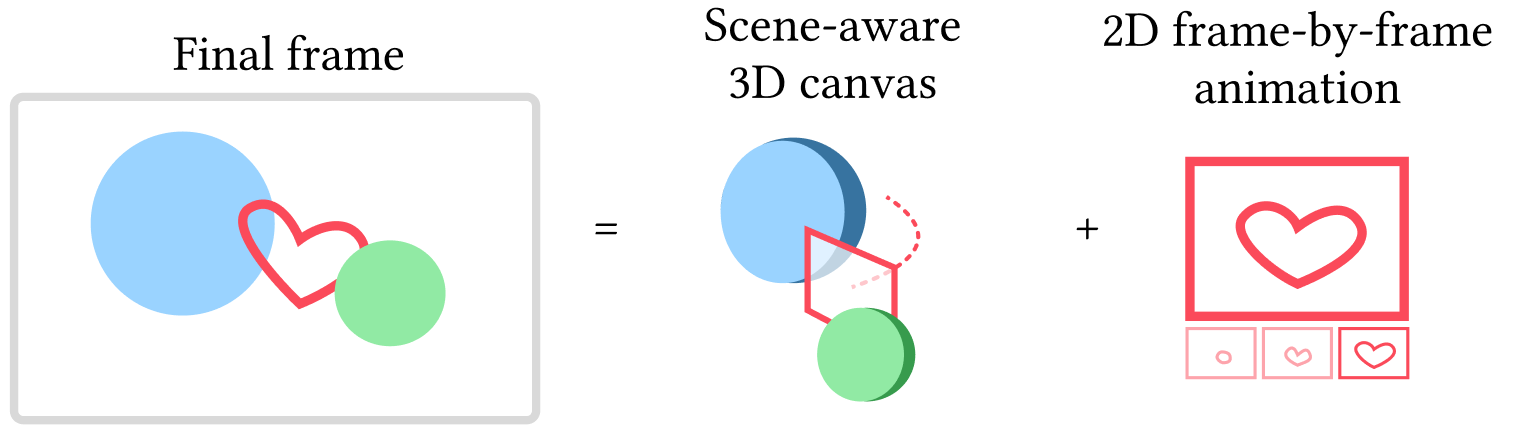
In our system, the final frame is obtained by rendering our scene-aware canvas in a partial 3D reconstruction of the captured scene. The user draws animated doodles onto this canvas.
Users can finely control the canvases with in our 2D image-space UI by keyframing position and orientation. Our system takes care to interpolate keyframes by tracking the motion of moving objects in the video.
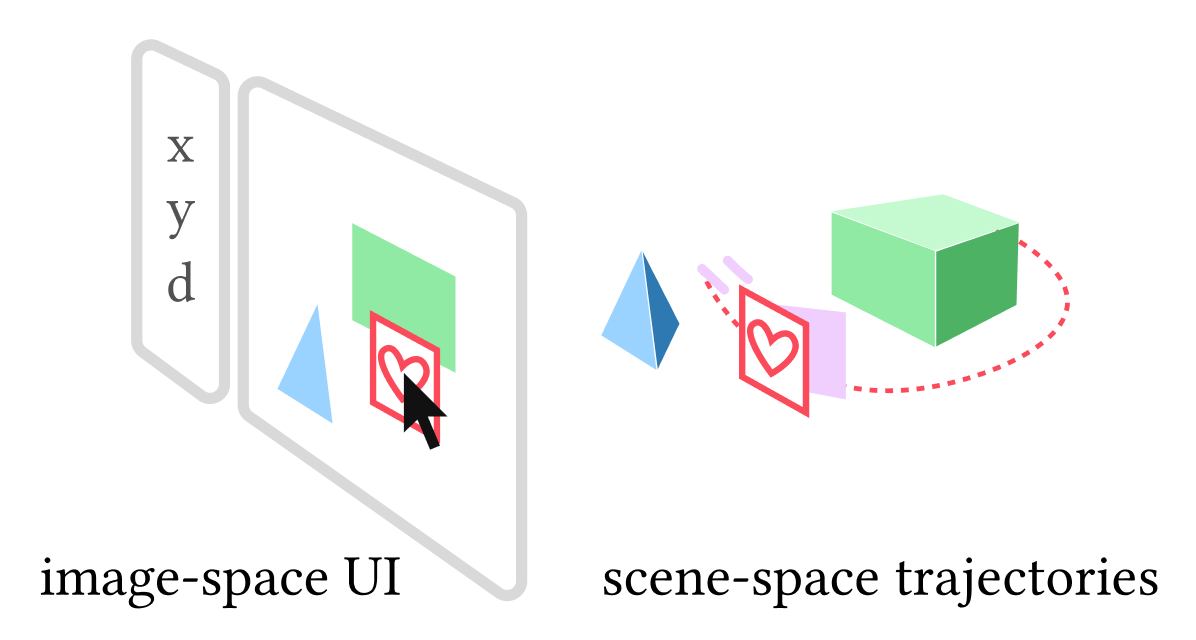
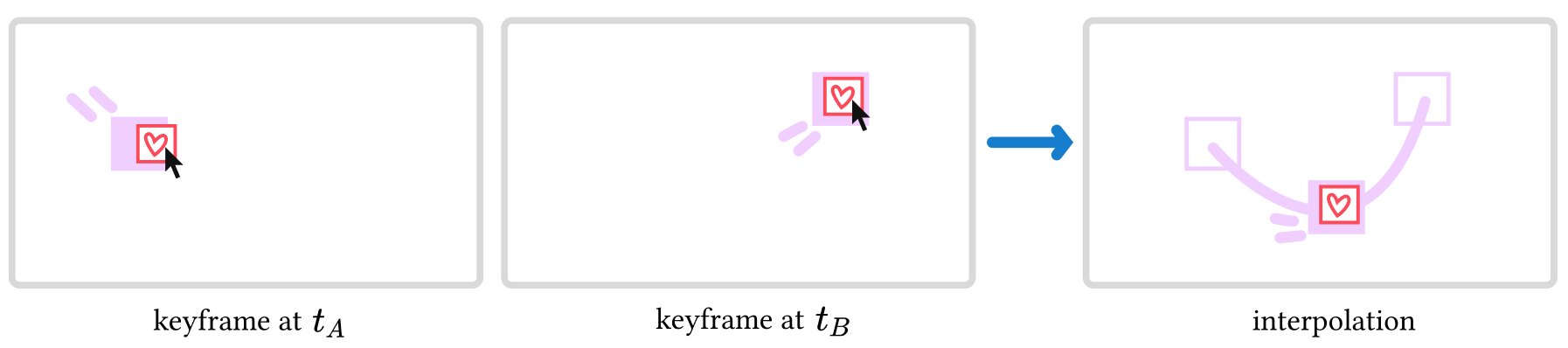
In a nutshell, we introduce a novel UI and tracking algorithm to unlock new edition capabilities for videos augmented with depth and motion data (obtained via existing computer vision methods). From user intent expressed through an arbitrary number of position and orientation keyframes, our algorithm can render a scene-aware canvas at any frame of the video with correct occlusions, perspective transformation and make the canvas follow a moving object.

With an orientation+position keyframe at the first frame (red) and a position keyframe at the last frame (green), our system renders the corresponding canvas coherently throughout the video.
Here is an overview of the workflow from the user’s perspective (see the video for more details):

Video
Acknowledgments
We thank our study participants for their time and effort, Wilmot Li for inspiration all along the project, Pascal Tempier for infrastructure support, Nicolas Rosset for help with testing the user interface, Felix Hähnlein, Timothée De Graeve, Rubaiat Habib and his daughters for appearing in or providing input footage. We thank the content creators of all tutorials cited in Supplemental Materials for sharing valuable information on how to make video doodles, and we thank LeopARTnik, Joseph Diaz and @murtsell for inspiring us and permitting usage of their creations as examples in the accompagnying video. We thank the anonymous reviewers for their helpful comments. This work was supported by ERC Starting Grant D3 (ERC-2016-STG 714221), and by software and research donations from Adobe.